
SD大模型种类对比
分别介绍一下各类主流生图大模型的主要特点,初步了解各类大模型的使用特点和使用方法。
SDXL
对提示词的包容度变的非常高,不需要额外质量提示词,对意境、氛围还原更到位。
能够更好的识别自然语言,可以直接使用常用语句描述场景。
更大更高清的分辨率,最好以1024分辨率为基础出图。
增加了Refiner优化模型,可以把跑出来的图用这个模型再跑一遍,或者前半段在Base上跑后半段在Refiner上跑,推荐切换时机0.8,以丰富细节,Refiner迭代步数越高越精细。
生成内容更加准确,可以初步生成简单英文和初步画好手,但仍会有错误。
XL为使用者提供了更丰富的艺术风格选项。
默认不可见水印。
SDXL_lightning
底模模式。直接使用SDXL-lightning底模,支持2-8步的采样,推荐4步;
UNET模式。使用UNET,最低支持1步,但官方表示,1步可能不稳定,建议2步;
LoRA模式。通过加载LoRA方式加速,支持支持2-8步的采样,推荐4步;
配合的采样器推荐使用SGM Uniform调度器,效果最好。
大模型为lightning模型时,不需要lightning的lora模型配合使用。
大模型为其他的XL模型时,可以和lightning的lora模型配合使用,让普通的XL模型在4步情况下,生成速度和质量有一样效果。
完整的 UNet 模型具有最佳质量,而 LoRA 模型可以应用于其他基础模型。
SDXL_lightning的速度跟TURBO模型差不多,但是它出的图比TURBO模型精美。
SDXL_lightning的lora模型跟之前的lcm的lora模型的作用都是可以加快我们的生图速度。
负面提示词无效果。
Turbo
采样器选择支持最好的Euler a或者LCM。
迭代步数为1步,CFG改成2以下。
最理想的出图大小时512*512左右,目前模型版本分辨率还不能去到1024级别。
LCM
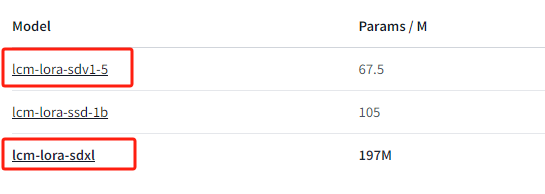


选择任意大模型。
采样方法选择Euler a或者LCM,迭代步数设为5,CFG改成1。
添加LCM的Lora进提示词。
点击生成。
SD1.5模型下,5步的速度比1步的SDXLTurbo还要快。
SDXL模型下,比普通SDXL模型要快30%,但没有SDXLTurbo快。
目前还是1.5版本的LCM技术更适合stablediffusion的webui平台。
同样的参数下,采用高分辨率放大2倍,LCM细节表现有显著的提升。
Euler a放大的画面已经开始有过度拟合的情况出现。
DPM++ 2M Karras采样器放大效果不能看。
Turbo+LCM
效果上Turbo+LCM双融合>Turbo单融合>LCM单融合。
这种模型至少需要5步以上才能生成好的效果图片。
不过它解决了SDXL Turbo分辨率不足的问题,可以出1024分辨率的图片。

Stable Cascade
对提示词理解比XL更强。
生成速度比XL更快。
把刚才下好的stage b和stage c,放到ComfyUI的models文件夹下的unet文件夹。
- 然后呢把stage a 放在models文件夹下的VAE文件夹。
stage a 在 huggingface 的 text encoder 目录里。
把text encoder文件夹下的model.bf16.safetensors,放到这个models文件夹下的clip文件夹下。

stage_c:主要负责图像推理和潜空间噪声的大模型。也是最消耗显存的模型。如果跟SDXL模型对比,可以理解为SDXL的Base大模型
stage_b:可以理解为相当于SDXL的refiner模型。主要负责接受stage_c传递过来的图像噪声,通过stage_b模型完成后续图片的生成。噪声在stage_b的Ksampler中完成
stageB_Conditioning:这个节点主要的作用就是用来接受stage_c噪声后的图像
StableCascade_EmptyLatentImage中的compression是指压缩比例。官方推荐1024*1024的SDXL比例像素,压缩值设置为42-50之间即可。太高和太低出图效果都不好。
StableCascade_StageB_Conditioning节点是将stage_c处理的图像传递给Stage_b模型对应的ksampler中。Stage_b的ksampler不需要negative反向提示词。
load clip:Load CLIP中需要加载cascade专用的model.safetensors来对图像进行CLIP层中进行处理。可以理解为通过这个模型在Clip层中对图像进行分层推理。
stage_a:这个模型可以理解为sdxl的vae模型。是cascade模型对应的vae模型。通过这个模型对图像进行编码和解码操作
ImageSharpen:锐化功能
EnhanceImage:图像增强功能
StableCascade暂时不支持Lora和Controlnet以及其他生态模型的加载。也不能配合SD1.5等其他的模型进行混合使用。
整体而言这个StableCascade还是未来可期的。它可以通过更少的步数和cfg达到超于SDXL质量的图。而且速度比SDXL快了30%-40%。如果以后生态形成,支持lora和controlnet等功能,那么会有质的提升。S
Playground V2.5

CosXL和CosXL_Edit
SD3
增加了文字渲染能力,可以准确的生成文字信息。
对提示词的识别能力显著提升,这得益于t5xxl的大语言模型。
可以直接使用汉字提示词。

图片质量得到了大幅的增强,开源版本的训练参数最高达到了20亿。

Kolors
可以直接使用中文提示词。
可以直接生成中文在图片上。
对复杂语义理解不错。