
GroundingDino是什么模型,起什么作用
GroundingDino简介
GroundingDINO是一个强大的目标检测模型,它结合了视觉和文本信息,能够在图像中检测并识别出与给定文本描述相符的对象。 它可以检测任何对象,而不仅仅是训练过程中见过的特定对象。Grounding DINO比GLIP推理速度更快,但在要求实时检测场景中考虑起来仍然推理速度太慢。
GroundingDino详解
GroundingDino可以简单的理解为检测一切,通过输入文字我们就能在图片上找到对应的物品。

如上图所示,我们观测左边的图像,我们输入提示词类别椅子(chair) , 属于COCO数据集的某个类别。该模型成功地检测到了这张图像上所有的椅子(chair)对象,检测结果很完美。 对于右边的图像,我们试图输入提示词狗的尾巴(dog's tail),显而易见,这个类别 当然不在任何常用的数据集中,但它仍然可以让模型正常检测识别,并给出正确的结果。
GroundingDino模型:
下载地址:https://github.com/storyicon/comfyui_segment_anything?tab=readme-ov-file
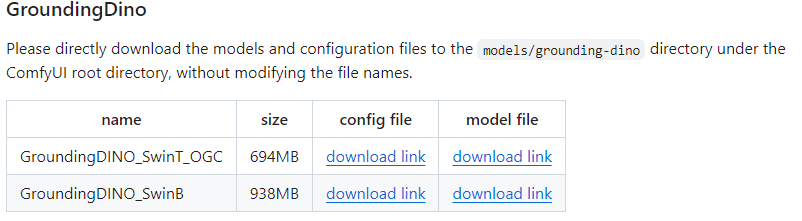
GroundingDino模型区别
GroundingDINO_SwinT_OGC和GroundingDINO_SwinB是两种不同的模型,它们之间的主要区别在于模型的大小、性能以及适用场景。
模型大小:
GroundingDINO_SwinT_OGC是一个相对轻量级的模型,其文件大小为694MB1。这里的“SwinT”代表“Swin Transformer Tiny”,意味着该模型在参数数量和计算复杂度上相对较低。
GroundingDINO_SwinB则是一个较大的模型,文件大小为938MB1。这里的“SwinB”代表“Swin Transformer Base”,意味着该模型在参数数量和计算能力上更强。
性能:
GroundingDINO_SwinT_OGC在处理速度上更快,因为它具有更少的参数和更低的计算复杂度。然而,在处理复杂任务和需要更高准确性的场景中,它的表现可能会稍逊于GroundingDINO_SwinB。
GroundingDINO_SwinB在性能上更强,因为它有更多的参数和更高的计算能力。这使得它在处理复杂任务和需要高精度的场景中更具优势,但相应地,它的处理速度可能会稍慢一些。
适用场景:
如果你需要快速处理图像并且可以接受稍低的准确性,那么GroundingDINO_SwinT_OGC模型可能是更好的选择。
如果你的任务需要更高的准确性,特别是在处理复杂图像和场景时,那么GroundingDINO_SwinB模型会是更好的选择。
GroundingDino参考资料
GroundingDINO根据文本提示检测任意目标:https://zhuanlan.zhihu.com/p/675302234
GroundingDINO的使用以及最详细源码讲解:https://zhuanlan.zhihu.com/p/680808735