
AI绘画模型-SD3.5
SD 3.5通常是指Stable Diffusion 3.5。OpenAI开发的一种基于深度学习的文本到图像生成模型。SD 3.5在之前版本基础上进行了改进。它使用大量的文本 - 图像对数据进行训练,通过学习文本描述和图像内容之间的关联,从而能够根据输入的文本提示生成对应的图像。
一、简介
模型架构特点
**Transformer架构**:它以Transformer架构为基础,Transformer架构具有高效的并行计算能力和长序列处理能力。在SD 3.5中,这种架构能够很好地处理文本和图像信息之间的映射关系。例如,它可以同时关注文本描述中的多个语义元素,如物体、颜色、场景等,并将这些元素准确地转换为图像中的相应内容。
**Diffusion过程**:采用扩散(Diffusion)过程来生成图像。简单来说,模型从一个随机噪声开始,通过逐步去噪的方式,根据给定的文本提示引导生成图像。这个过程类似于从混乱中逐渐构建出有序的图像,每次去噪步骤都利用模型学到的知识来调整图像内容,使其更符合文本描述。
二、版本介绍
三个版本
SD 3.5 Medium 训练参数26亿
SD 3.5 Large turbo 训练参数81亿
SD 3.5 Large 训练参数81亿 采样步数设置28步以上才能体现出SD 3.5的最好水平,CFG推荐在4-5之间。
版本比较
三个版本都低于FLUX.1的训练参数120亿,但质量好换不能单凭训练参数多少来分辨。
Large turbo 相比 Large 生成速度更快,但细节效果较少,但也足够好了。
三、优势与局限性
**优势**
支持更多风格:高度灵活性,从写实风格到抽象风格、从古代场景到未来科幻场景等都可以通过文本提示来实现。
出图多样性
人物多样性:SD3.5模型在人物多样性方面表现出色,能够生成更加多样化和逼真的图像。
画面美感提升:SD3.5模型能够提供更真实的图像输出,特别是在写实和游戏设计方面。
拓宽商用许可:年收入低于100W美元的公司个人可以商用,但不能用于盈利。
**局限性**
细节和准确性有限:尽管它能生成不错的图像,但在细节方面可能不够精确。比如在生成复杂机械结构的图像时,可能会出现结构不合理的情况。
语义理解偏差:有时会对输入的文本提示产生误解。例如,输入“一只戴着红色帽子的蓝色小狗”,可能会生成一只红色小狗戴着蓝色帽子之类的不符合预期的图像。
四、安装方法

下载 ClipL、Clip G、T5 三个模型,Comfyui放到根目录/models/clip/里面,webui放到根目录/models/CLIP里面。
下载 SD 3.5 Large、SD 3.5 Large Turbo,Comfyuii放到根目录/models/checkpoints/里面,webui放置到根目录/models/Stable-diffusion/里面。
五、使用注意
1、clip模型加载
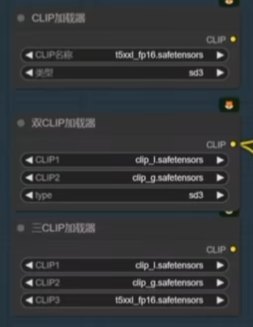
如图三种方法皆可,但第三种非常消耗显存,我的3060 12g 显卡搞不定,会爆显存。
2、提示词
对负面提示词要求不高,可以把负面提示词通过“条件零化”节点简化掉。
3、大模型
SD 3.5大模型在生成满意图片后,可以选择在大模型之后串联上”模型采样算法SD3“偏移节点再次生成以进行微调,能够在画面细节和清晰度上一定程度的加强。但不能设置的过低或过高,不然对原始画面有较大的改变,推荐设置在2-3之间比较合适。
4、采样器和调度器
SD 3.5 Large:步数28步以上,CPG4-5,采样器euler 或者 dpampp_2m,调度器sp_uniform, beta。
SD 3.5 Large turbo:步数4步,CFG 1.2 ,推荐使用的是 euler 加 sgm uniform 搭配。
六、应用领域
**艺术创作**:
为艺术家提供灵感。比如,一位插画师想要创作一幅带有奇幻色彩的森林场景图,他可以输入“一片充满魔法生物的奇幻森林,有发光的蘑菇和会飞的小精灵”这样的文字描述,SD 3.5就能生成一个初步的图像概念,艺术家可以在这个基础上进行二次创作。
**广告设计**:
广告公司可以利用它快速生成产品广告创意。例如,要设计一个运动鞋广告,输入“一双时尚的运动鞋在城市街道上奔跑,周围有炫酷的光影效果”,模型生成的图像可以帮助设计师快速捕捉创意灵感,设计出更吸引人的广告。
**内容生成辅助**:
对于内容创作者,如写小说、制作游戏剧情等,它可以生成与内容相关的图像来辅助说明。比如一个游戏剧情策划师在设计一个新的关卡场景时,用SD 3.5生成关卡场景的草图,让团队成员更好地理解场景构思。