
Comfyui各种条件节点详解
Comfyui的条件节点众多,我们最熟悉不过的正向提示词和负面提示词就是最典型的条件节点,绝大多数条件节点都是添加在加载器和K采样器之间的。条件节点的主要作用就是充当指挥官,下达命令,告诉comfyui要生成什么样的图片。
| 风格模型 | 风格模型应用 | |||||
| ControlNet | ControlNet应用(旧版) | ControlNet应用(旧版高级) | ControlNet应用 | 设置UnionControlNet类型 | ControlNet应用_阿里妈妈局部重绘 | Set Shakker Labs Union ControlNet Type |
| GLIGEN | GLIGEN文本框应用 | |||||
| 局部重绘 | 内补模型条件 | |||||
| 视频模型 | SVD_图像到视频_条件 | LTXV图像到视频 | LTXV条件 | |||
| 3D模型 | SZ123条件 | SZ123条件(批次) | SV3D_条件 | |||
| 放大扩散 | SD4X放大条件 | |||||
| StableCascade | StableCascade_StageB条件 | |||||
| InstructPix2Pix | InstructPixToPix条件 | |||||
| 高级 | CLIP文本编码器(BNK) | CLIP文本编码器(BNK-SDXL) | 添加SDXL参数 | 添加SDXL优化参数 | ||
| CUIP文本编码器 | ||||||
| CLIP设置停止层 | ||||||
| 条件平均 | ||||||
| 条件合并 | ||||||
| 条件联结 | ||||||
| 条件采样区域 | ||||||
| 按系数设置条件采样区域 | ||||||
| 条件采样区域强度 | ||||||
| 条件设置遮罩 | ||||||
| CLIP视觉编码 | ||||||
| unCLIP条件 | ||||||
| StableAudio条件 | ||||||
| CLIP Text Encode++ |
内补模型条件-InpaintModelConditioning
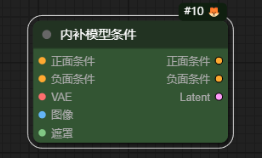
作用:内补=inpaint(局部重绘),它的作用就是局部重绘
接口
输入
正面条件:接入正向提示词节点
负面条件:接入负向提示词节点
VAE:接入VAE模型
图像:接入加载图像节点加载的图像
遮罩:接入加载图像节点绘制的遮罩
输出
正面条件:输出正向提示词到采样器
负面条件:输出负向提示词到采样器
Latent:输出潜空间
SVD_图像到视频_条件-SVD_img2vid_Conditioning
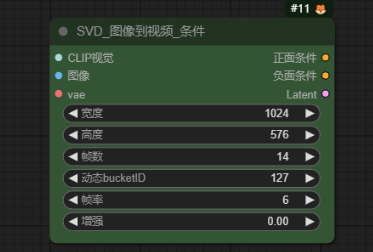
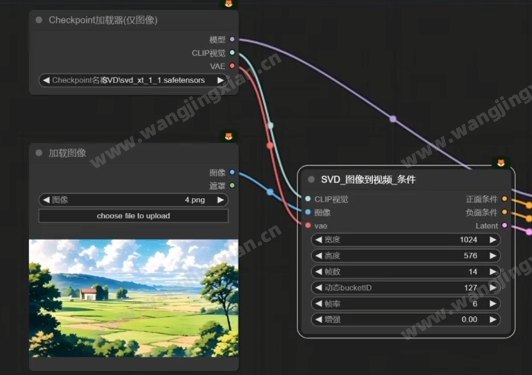
作用:SVD是stablediffusion自主研发的图生视频模型,可以让一张图片直接变成一段简短的视频。一般前接Checkpoint加载器(仅图像)节点。
接口
输入
CLIP视觉:输入加载器节点上的CLIP视觉模型
图像:输入图像
vae:输入vae模型
输出
正面条件:输出正向提示词
负面条件:输出反向提示词
Latent:输出潜空间
参数
宽度:设置潜空间宽度
高度:设置潜空间高度
帧数:设置视频帧数,也就是视频总共的帧数长度
动态bucketID:Bucket代表了对象存储服务(OSS)中的一个存储空间,用于存放输入文件,如初始图像等。动态bucketID则特指这个存储空间在某一时刻或某种状态下的唯一标识。
帧率:设置视频帧率
增强:“增强”参数通常指的是对视频质量或特定效果的加强处理。如视频分辨率的提升、色彩饱和度的增强、细节锐化等。
SZ123条件-StableZero123_Conditioning
SZ123条件(批次)-StableZero123_Conditioning_Batched
SV3D_条件-SV3D_Conditioning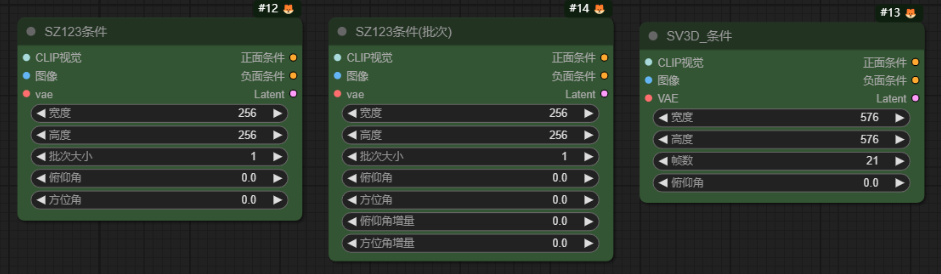
作用:这几个节点都是用来生成3D多视角视图使用的,它们的区别在于前面两个是需要搭配 stable_zero123.ckpt 模型来使用,而最后这个配合 SV3D.ckpt 模型来使用,使用方法都一样。
接口
输入
CLIP视觉:输入加载器节点上的CLIP视觉模型
图像:输入图像
vae:输入vae模型
输出
正面条件:输出正向提示词
负面条件:输出反向提示词
Latent:输出潜空间
参数
宽度:生成图片的宽度
高度:生成图片的高度
批次大小:生成几张图片
俯仰角:俯仰视角的调整,值为度数
方位角:左右视角的调整,值为度数
俯仰角增量:每张图片在俯仰视角依次递增的角度
方位角增量:每张图片在左右视角依次递增的角度
SD4X放大条件-SD_4XUpscale_Conditioning
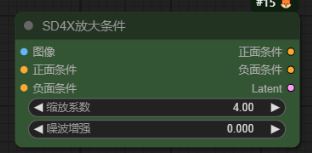
作用:它的作用就是让我们的图片进行4倍放大后再进入潜空间进行采样降噪处理。需要下载这个stablediffusion专门4倍放大的模型“stable-diffusion-x4-upscaler”,用加载器加载。
参数
缩放系数:放大倍数
噪波增强:增加细节,值在0~1之间,每增加0.1则细节增加0.1
StableCascade_StageB条件-StableCascade_StageB_Conditioning
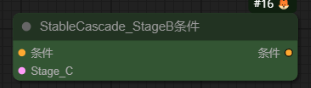
作用:这个是stableCascade模型专门的条件节点,可以看到这里有stageB和stage C的参数,这是由于stableCascade模型是具有三阶串联的新特性的。
InstructPixToPix条件-InstructPixToPixConditioning
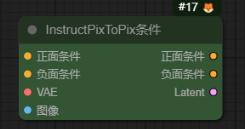
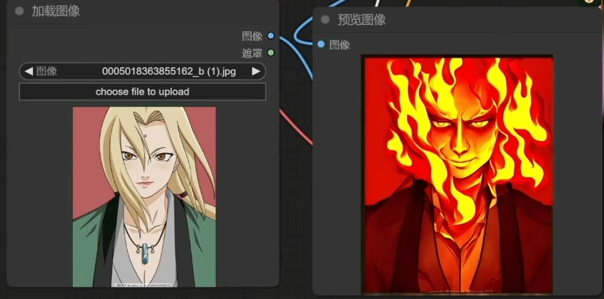
作用:这个节点的作用就是可以通过提示词在我们上传图片的基础上赋予一系列新的样式风格。要让这个节点生效,需要下载一个cosxl的大模型 cosxl_edit_.safetensors。这个模型也是stabilty官方研发的,在huggingface里面就可以搜索下载到。
例子:例如输入makeit fire,让它着火。生成的图片内容就会着火。
CLIP文本编码器-CLIPTextEncode
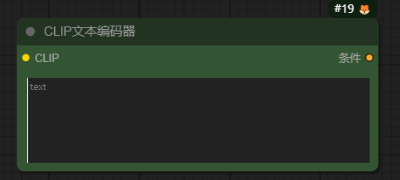
作用:这个就是我们最为熟悉的正向提示词和负面提示词的条件输入框了。
CLIP设置停止层-CLIPSetLastLayer
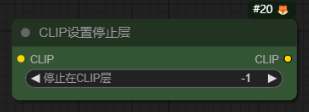
作用:不好解释
使用方法:跟lora节点一样,直接串联在大模型的后面即可。一般情况下真实风:设置-1,动漫风:设置-2/
条件平均-ConditioningAverage
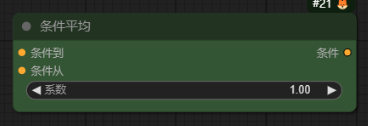
作用:连接两个正向提示词输入框,让两个正向提示词都起一定作用,具体哪个起多大作用看系数设置,设置为1时只有第一个提示词起作用,设置为0时只有第二个提示词框起作用,设置为0.5则两个都起一半作用。
条件合并-ConditioningCombine

作用:如果两个提示词框输入的提示词为同一个角色的独立元素(例如:条件1,一个女孩,条件而,红色头发),那生成的效果与条件联结没有区别;但如果两个提示词框为不同角色元素(例如:条件1,1个女孩,条件2,一条狗),则会把狗和女孩融合一起,生成一条拟人化动物。
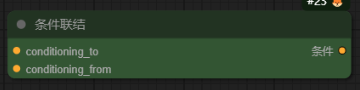
条件联结-ConditioningConcat
作用:连接两个正向提示词输入框,让两个正向提示词都起作用,并且不会互相污染。如果两个提示词框为不同角色元素(例如:条件1,1个白衣女孩,条件2,一条红衣狗),生成的图像可能出现多种情况,1、1个红衣女孩;2、1个女孩和1条狗;
条件设置遮罩-ConditioningSetMask
作用:这个节点是用来设定提示词的起效区域的。
CLIP视觉编码
unCLIP条件

作用:前接CLIP视觉加载器节点,加载clip模型学习图片风格。
条件采样区域
按系数设置条件采样区域
条件采样区域强度
SixGodPrompts
SixGodPrompts_Text
CLIP Text Encode++
风格模型应用
ControlNet应用
ControlNet应用(高级)
ControlNet应用_SD3/HunYuan
设置UnionControlNet类型
GLIGEN文本框应用
CLIP文本编码器(BNK)
CLIP文本编码器(BNK-SDXL)
添加SDXL参数
添加SDXL优化参数
https://www.bilibili.com/opus/1011958345800613894