
Comfy-WaveSpeed插件
介绍
wavespeed 测试下来,出图时间省了一半,图片质感又没缺失多少,这个wavespeed不仅针对图片加速,对生成视频也可以加速。
左下角是出图所用时间,左边是原图出图时间,中间是用上wavespeed里面一个加速功能的时间,右边是用了wavespeed2个功能的出图时间,直接翻倍了。

插件地址:https://github.com/chengzeyi/Comfy-WaveSpeed/tree/main
功能:支持FLUX 、 LTXV (native and non-native) 、 HunyuanVideo (native)和SDXL等多种模型。
原理
受TeaCache和其他去噪缓存算法的启发,引入了第一块缓存(FBCache),使用第一个Transformer块的残差输出作为该高速缓存指示器。如果当前和第一个Transformer块的先前残差输出之间的差足够小,则可以重用先前的最终残差输出,并跳过所有后续Transformer块的计算。这可以显著降低模型的计算成本,在保持高精度的同时实现高达2倍的加速。主要有两个节点。
节点一:Apply First Block Cache
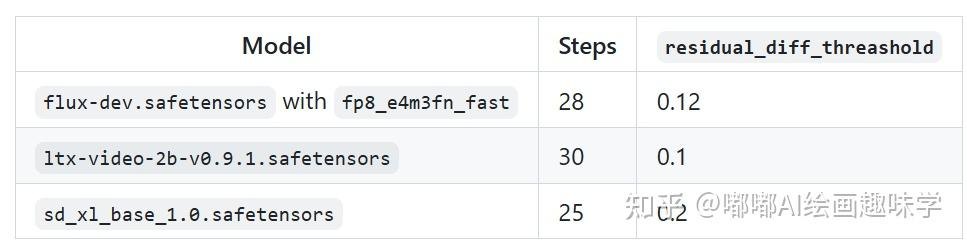
使用第一个块缓存,只需添加 wavespeed->Apply First Block Cache 在Load Diffusion Model节点之后将节点添加到工作流程,并将residual_diff_threashold值调整为适合模型的值,例如:对于具有fp8_e4m3fn_fast和 28 个步骤的flux-dev.safetensors为0.12 。预计速度将提高 1.5 倍至 3.0 倍,并且精度损失可接受。
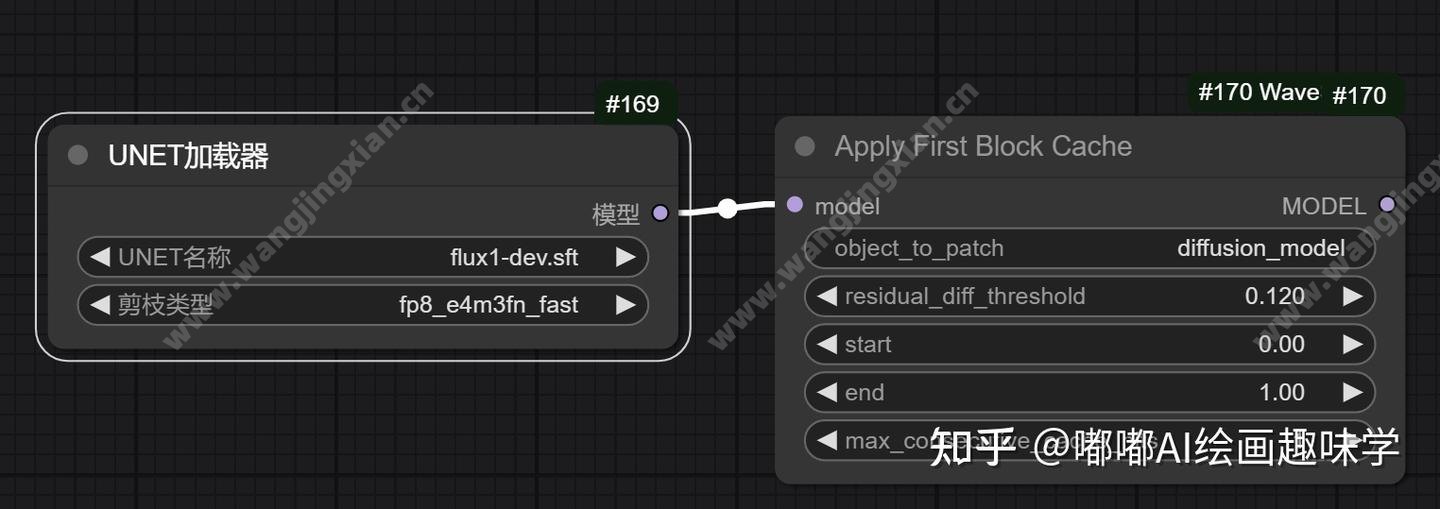
使用方法
要使用这个插件加速技术,对应的节点如下,在加载模型后面直接跟上这个Apply First Block Cache节点即可,很简单。
使用的话主要点有几点:
• 步骤至少要28步,这个加速主要是后半部分速度提升很快,如果步数太少了没效果。
• 权重推荐是设置0.12,数字越大,出图越快,但是值大了图就模糊了。
• 要用原生模型 dev fp16或者fp 8,不要用微调版本
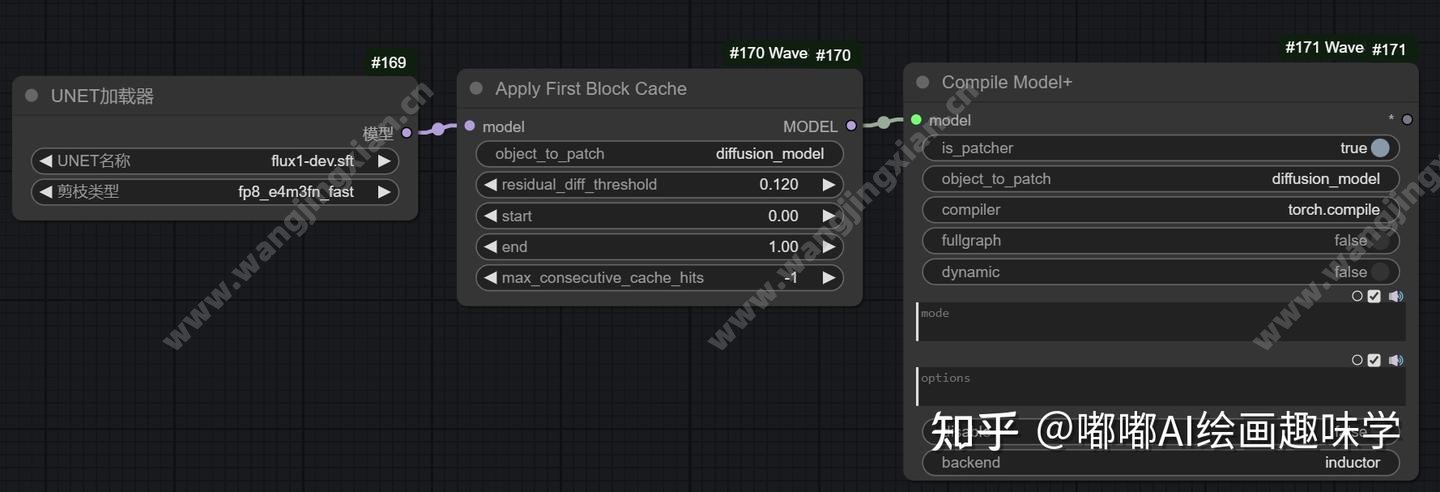
这一步速度提升大概是1.7倍。这还只是第一重提速,官方说明后面还有一个增强的,利用了 torch.compile技术,在上面 Apply First Block Cache节点后面再添加了一个 Compile Model+的节点即可。
节点二:增强torch.compile
window电脑使用这个torch.compile好像会报错,如果你也遇到如下这个错误,那就需要安装triton了。
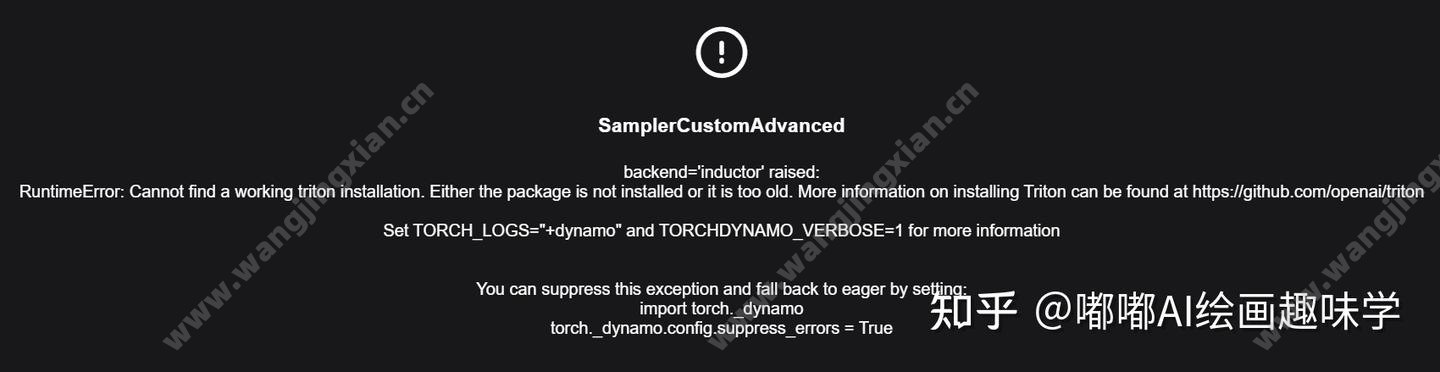
我查了资料,好像是对window电脑不是很兼容,需要自己去下载文件编译安装triton。
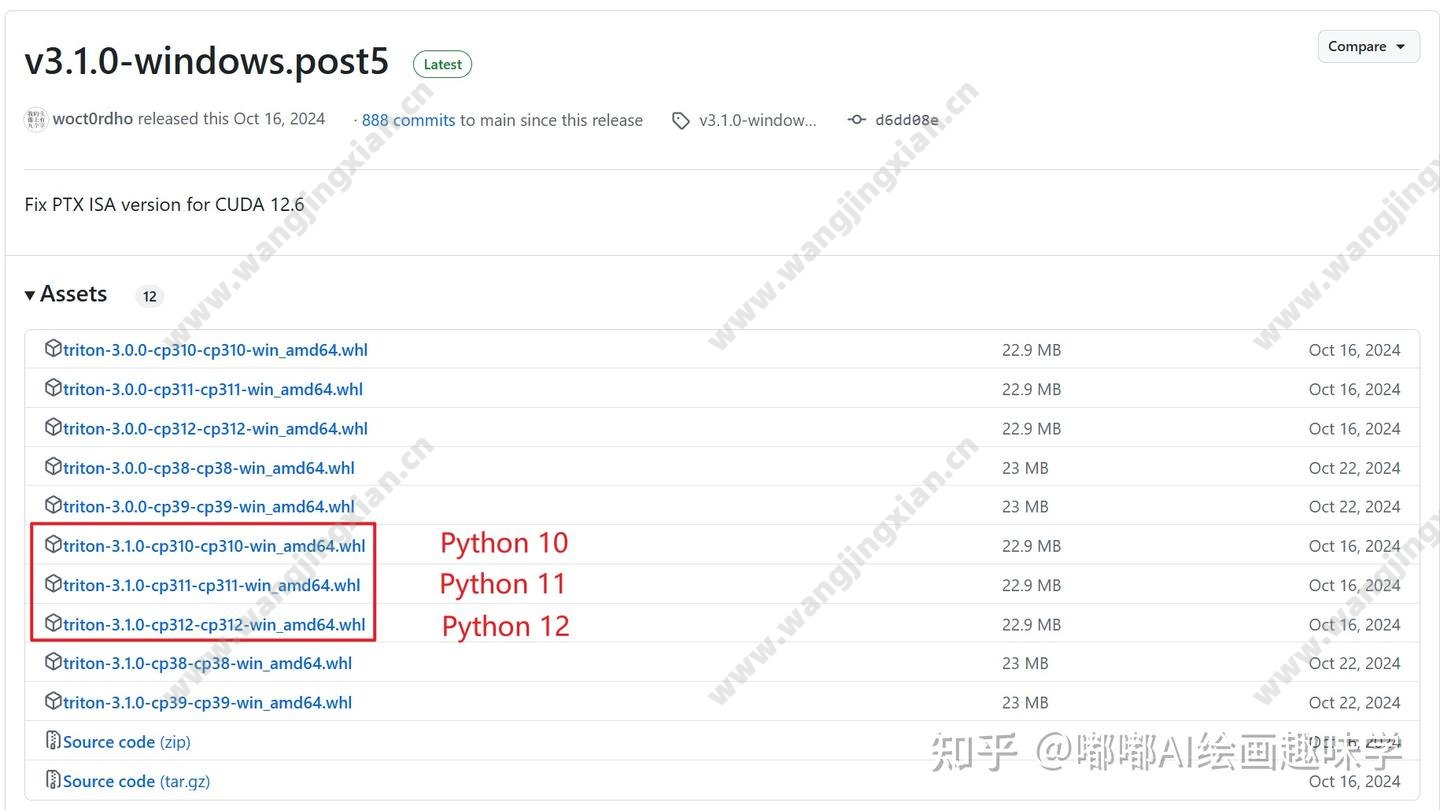
https://github.com/woct0rdho/triton-windows/releases/tag/v3.1.0-windows.post5
下载你电脑对应的python版本的包,我这里ComfyUI对应的是python 10,所以我就下载 triton-3.1.0-cp310-cp310-win_amd64.whl
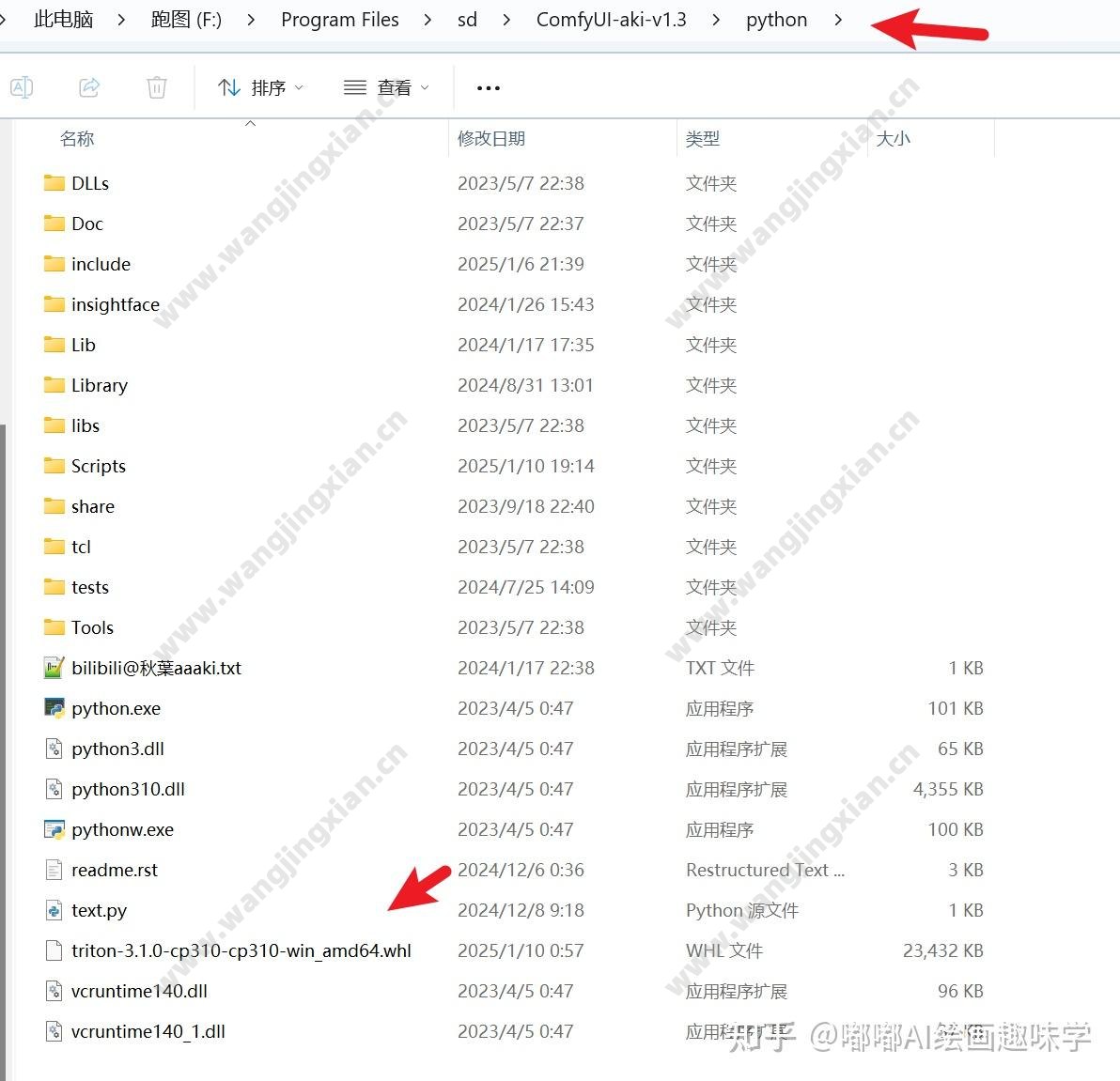
然后我把这个文件放到了ComfyUI下面的python目录下
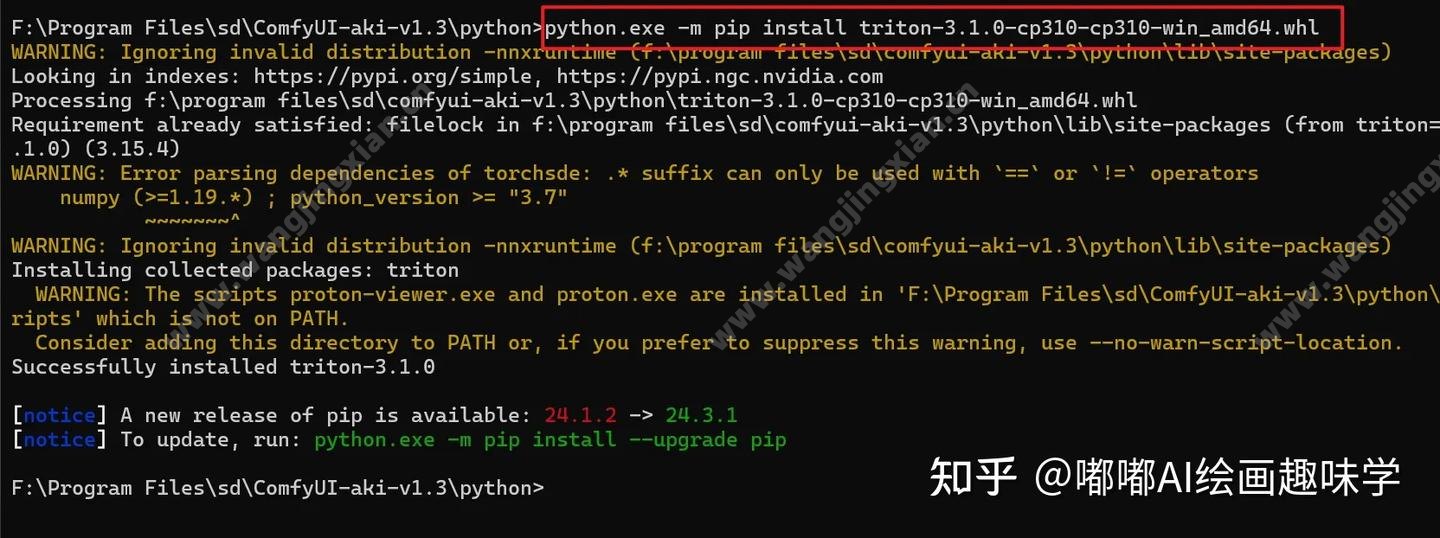
最后进入这个目录下的命令窗口,输入命令:
python.exe -m install triton-3.1.0-cp310-cp310-win_amd64.whl
就安装上这个 triton依赖包了。
然后就可以用了。我自己测试下来,同时使用Apply First Block Cache节点和Compile Model+节点,出图速度提升了2.3倍。
注意:使用 FP8 量化编译模型不适用于 RTX 3090 等 Ada 之前的 GPU,您应该尝试使用 FP16/BF16 模型或删除编译节点。