
Lumina-Image 2.0
Lumina-Image 2.0是一个由上海AI Lab开发的开源文生图模型,主要用于图像生成。该模型参数量仅为 2.6B,基于扩散Transformer(DiT)架构,融合了高效的图像编解码器(FLUX-VAE-16CH)和文本编码器(Gemma-2-2B)。
模型特点
高效性:Lumina-Image 2.0的参数量仅为26亿,相对于其他模型如Flux.1的120亿参数量,其体积更小但生成图像的质量较高且速度较快。
多语言支持:该模型支持直接使用中文、日语、韩语等多种语言提示词,提升了文本和图像的对齐效果。
开源性:Lumina-Image 2.0基于Apache 2.0开源,目前已在GitHub上提供了微调代码。
适用方法
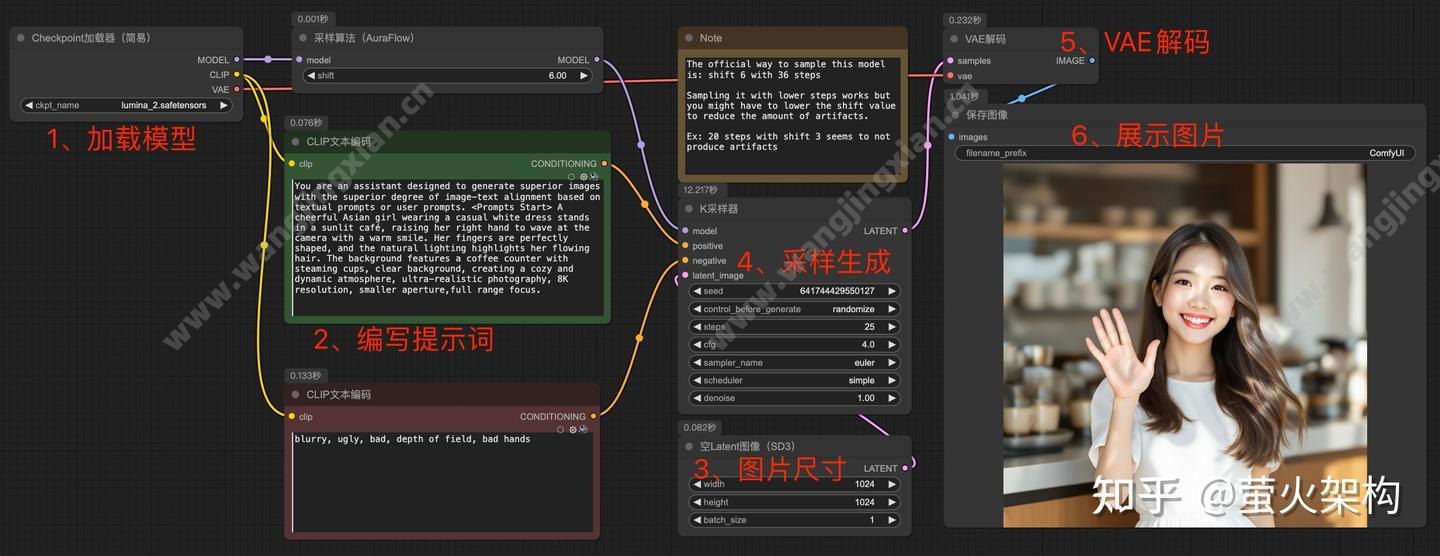
这里简单介绍下这几个采样参数:
采样器/调度器:默认为 eluer/simple,也可以尝试 res_multistep/simple、 ipndm/ays+ 等的组合。
采样步数:25-40,不同的生成任务可能需要进行调整,建议先使用25和40分别测试。
CFG:4-8,实测过高的CFG可能导致生成空白图。
图片尺寸:根据官方在huggingface的演示程序,高和宽建议范围:512- 2048。
负向提示词:Lumina Image 2.0 支持编写负向提示词,这一点与Flux.1模型有很大不同,我们生成内容有了更强的控制能力。
Lumina-Image 2.0的使用方法和我们常用的SD基础工作流使用方法一样,如下图:
应用场景
Lumina-Image 2.0可以应用于多种图像生成任务,包括写真、艺术字、风格化图像、逻辑推理图像、双语提示词以及图片加文字的引导生成等。此外,该模型在文本和图像一致性方面表现出色,能够更好地理解并生成符合提示词描述的图像。
参考
https://zhuanlan.zhihu.com/p/25221921950