
comfyui-florence2插件
Florence-2是一个由微软Azure AI团队推出的多功能视觉模型,Florence-2能够执行图像描述、目标检测、视觉定位和图像分割等多种计算机视觉任务。
插件
插件地址:https://github.com/kijai/ComfyUI-Florence2
模型地址:
官方:
https://huggingface.co/microsoft/Florence-2-base
https://huggingface.co/microsoft/Florence-2-base-ft
https://huggingface.co/microsoft/Florence-2-large
https://huggingface.co/microsoft/Florence-2-large-ft
https://huggingface.co/HuggingFaceM4/Florence-2-DocVQA
已测试微调:
https://huggingface.co/MiaoshouAI/Florence-2-base-PromptGen-v1.5
https://huggingface.co/MiaoshouAI/Florence-2-large-PromptGen-v1.5
https://huggingface.co/thwri/CogFlorence-2.2-Large
https://huggingface.co/HuggingFaceM4/Florence-2-DocVQA
https://huggingface.co/gokaygokay/Florence-2-SD3-Captioner
https://huggingface.co/gokaygokay/Florence-2-Flux-Large
https://huggingface.co/NikshepShetty/Florence-2-pixelpros
这些模型可以自动下载 DownloadAndLoadFlorence2Model 到 ComfyUI/models/LLM
节点
DownloadAndLoadFlorence2Model:下载需要的模型并加载
DownloadAndLoadFlorence2Lora:下载需要的Lora并加载
Florence2ModelLoader:当模型已经下载后,再次使用时就可以直接用这个加载模型
Florence2Run:运行,执行任务
详解
Florence-2-base:基础模型,
Florence-2-base-ft:基础模型的微调模型
Florence-2-large:较大的模型,
Florence-2-large-ft:较大的模型的微调模型
Florence-2-large-PromptGen-v2.0
Lama-3.1-8B-Lexi-Uncensored-V2
Lama-3.2-11B-Vision-Instruct-nf4
Meta-Llama-3.1-8B-Instruct
Phi-3.5-mini-instruct
Phi-3.5-vision-instruct
HuggingFaceM4/Florence-2-DocVQA:文档视觉模型
thwri/CogFlorence-2.1-Large
thwri/CogFlorence-2.2-Large
gokaygokay/Florence-2-SD3-Captioner
gokaygokay/Florence-2-Flux-Large
MiaoshouAI/Florence-2-base-PromptGen-v1.5
MiaoshouAI/Florence-2-large-PromptGen-v1.5
MiaoshouAI/Florence-2-base-PromptGen-v2.0
MiaoshouAI/Florence-2-large-PromptGen-v2.0
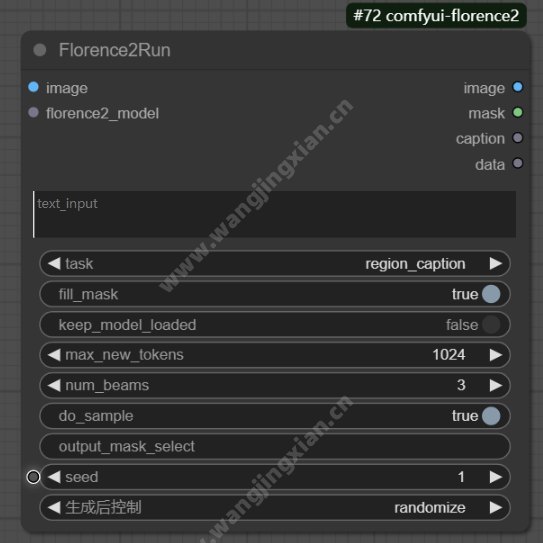
region_caption :识别图像中的特定区域,检测出图像中的各种元素,并对这些区域的元素呢进行一个描述
dense_region_caption:跟上面一样,只是更密集地描述图中更多区域,信息更丰富。
region_proposal:跟上面一样,但是但是它不会给出任何的提示信息了,不会告诉你这是什么那是什么。但是它会把每个区域都检测出来了,它检测的比上面两个检测的区域都要多。
caption:上面的都是遮罩的检测,这个是对图像的自然语言描述,相当于反推提示词。
detailed_caption:用几句话较详细地描述整张图。
more_detailed_caption:跟上面额一样,用更多细节描述整张图,但是这个最详细。
caption_to_phrase_grounding:支持在text_input中输入描述,进行任务互动。可以根据提示词描述检测图像中的元素,给出遮罩(bbox方形遮罩)、编号、文本信息和数据信息。当检查出多个遮罩,可以在output_mask_select里填写序号,选择一个或多个,支队mask的结果产生影响,其他3个结果不影响。
referring_expression_segmentation::支持在text_input中输入描述,进行任务互动。跟上面的差不多,支持检测出来的遮罩不是bbox的方形遮罩了,而是精确的检测出来,但实际效果不如其他插件。另外没有编号和数据信息。多次检测或不同模型检测出来的结果会不一样。
ocr:从图像中识别提取文本,可以输入图像和视频,但只支持英文。
ocr_with_region:提取文字并标出其在图中的位置。
docvqa:文档视觉问答,你提问在text_input中输入描述,进行任务互动。它从文档中找答案,像对话模型一样对话。
prompt_gen_tags:对文档的总结,必须配合文档视觉模型Florence-2-DocVQA。
prompt_gen_mixed_caption:生成关键词+短句混合的 AI绘图提示词
prompt_gen_analyze:分析图像结构,生成层级提示词
prompt_gen_mixed_caption_plus:更完整丰富的绘图提示词输出